ergebnisse mit dem stable diffusion modell
ControlNet
, bei dem man ein eingabebild analysieren läßt, um eigenschaften wie umrisse, tiefe, körperhaltung o.ä. zu bekommen.
mit diesen informationen ("checkpoint") und einem text läßt man stable diffusion dann ein ausgabebild erzeugen.
es gibt acht verschiedene modelle, ich habe "lllyasviel/sd-controlnet-scribble" verwendet, das skizzen gut analysieren kann.
das ganze habe ich logischerweise wieder mal auf meine aktskizzen losgelassen. nichts hiervon ist großartig optimiert, sondern das ist mehr oder weniger das erste was herausgepurzelt kam:
| eingabebilder (meine alten skizzen) |
ausgabebilder |
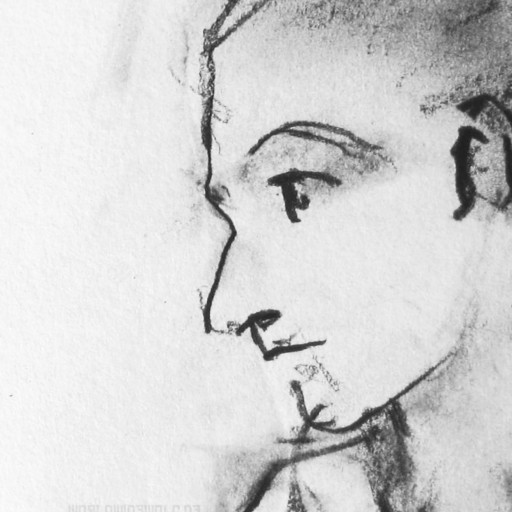 | 
bleistiftskizze von egon schiele
|
 | 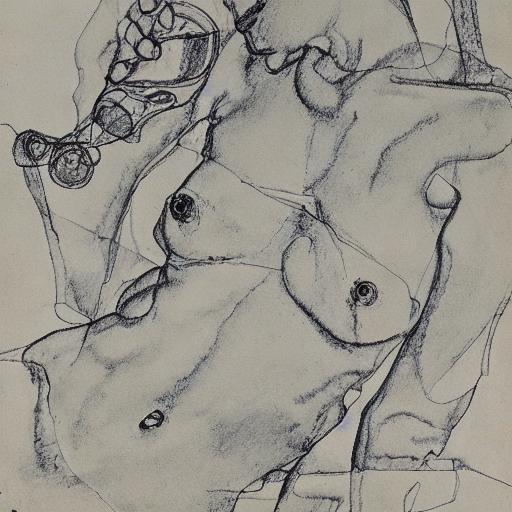 
bleistiftskizzen von egon schiele
(ich sehe mich ja eigentlich selbst als so eine art schiele, aber wenn man die bilder hier so sieht erkennt man,
daß schiele selbst doch mehr schiele war als ich. naja. dafür bin ich mehr da vinci als schiele da vinci war.)
|
 |  
der text war im grunde nur frau am strand, die bademode hat stable diffusion aufgrund meiner skizze entworfen
|
 | 
ich überlege, ob ich die bademoden zum patent anmelde. immerhin sind die ja durch schatten in meinen skizzen entstanden...
|
 | 
das bild hat zwar jede menge fehler, zeigt aber möglicherweise einen kommenden modetrend: irgendwelchen wirr zusammengestrickten stoff irgendwo und irgendwie getragen. sogenannte "KI mode".
|
|  
ich habe dann noch 5 weitere checkpoints ausprobiert und festgestellt, daß "lllyasviel/sd-controlnet-hed" die skizze korrekt erfaßt und alle! ergebnisse die geometrie der vorlage haben.
nur die farben laufen mit "hed" aus dem ruder. vielleicht gucke ich später nochmal, ob es noch irgendeinen versteckten parameter oder trick gibt.
ich habe, glaube ich, irgendwo noch was von multi-controlnet oder so gelesen, um mehrere checkpoints zu kombinieren, bin aber zu faul nachzusehen.
in ein paar monaten ist das eh gelöst und ein bild-zu-bild diffusionsmodell wird jedes denkbare bild erzeugen. vermutlich mit umgangssprachlicher texteingabe ohne irgendwelche parameter.
ich finde die jetzigen ergebnisse jedenfalls cool und vielleicht sind die sogar besser als fotorealistische bilder.
ich meine, will ich denn ein exakt rekonstruiertes modell hinter meiner skizze wirklich sehen oder ist eine ungefähre vorstellung nicht näher an der zeichnung?!
vielleicht ist stable diffusion für aktskizzen bereits in einem lokalen optimum.
|
... und wenn man auf so einer fehlfarbenausgabe ein instruct-pix2pix modell mit der eingabe "fix colors" rechnen läßt, kommt ein bild raus, das halbwegs realistisch ist:


das rechte bild ging also von der frau durch mein gehirn auf die zeichnung und anschließend durch drei neuronale netzwerke.
schwer zu sagen, ob das bild noch irgendetwas mit realität zu tun hat, zumal das instruct-pix2pix modell ja wieder fehler reinbringt.
meiner erinnerung nach ist das im großen und ganzen ziemlich korrekt, nur ob meine erinnerung nach 10 jahren noch stimmt, wage ich mal zu bezweifeln.
oh. ich sehe gerade: die hat ja gar nichts an : /

die qualität der skizze spielt übrigens keine rolle. hier noch meine 30 sekunden skizze eines liegeradfahrers vom letzten jahr : )


mein fazit: controlnet ist ein weiterer meilenstein richtung zauberei.
man kann damit allgemein die von stable diffusion erzeugten bilder viel besser beeinflussen als vorher.
und beispielsweise sehen, wo an einer skizze ein schatten falsch gezeichnet war oder wo was wie besser zu zeichnen gewesen wäre.
das linke schulterblatt in der rückenaktskizze habe ich zum beispiel vergurkt. das daraus erzeugte bild zeigt, wie es anatomisch korrekt gewesen wäre.
und das eine open source software mir im detail zeigt wie egon schiele die anatomie meiner aktskizzen gezeichet hätte, hätte ich vor einem jahr noch für vollkommen! utopisch gehalten.
stable diffusion seite